
บทคัดย่อ: อภิปรายโอกาสและการพัฒนาของ DataFi เช่นเดียวกับวิธีการมีส่วนร่วมในโครงการ DataFi ยอดนิยมในปัจจุบัน ผู้เขียน: ผู้สนับสนุนหลัก Biteye @anci_hu49074
“เราอยู่ในยุคแห่งการแข่งขันระดับโลกเพื่อสร้างแบบจำลองพื้นฐานที่ดีที่สุด พลังการประมวลผลและสถาปัตยกรรมแบบจำลองมีความสำคัญ แต่อุปสรรคที่แท้จริงคือการฝึกฝนข้อมูล”
—Sandeep Chinchali, หัวหน้าฝ่าย AI, Story
ประเด็นร้อนแรงที่สุดในวงการ AI เดือนนี้คือ Meta ที่แสดงให้เห็นถึงศักยภาพทางการเงิน ซักเคอร์เบิร์กได้สรรหาบุคลากรที่มีความสามารถจากทั่วทุกมุมโลกและก่อตั้งทีม Meta AI สุดหรูที่ประกอบด้วยนักวิจัยทางวิทยาศาสตร์ชาวจีนเป็นหลัก หัวหน้าทีมคือ อเล็กซานเดอร์ หวัง อายุเพียง 28 ปี ผู้ก่อตั้ง Scale AI เขาเป็นผู้ก่อตั้ง Scale AI และปัจจุบันมีมูลค่า 29 พันล้านดอลลาร์สหรัฐ หน่วยงานที่ให้บริการประกอบด้วยกองทัพสหรัฐฯ รวมถึง OpenAI, Anthropic, Meta และบริษัท AI ยักษ์ใหญ่คู่แข่งอื่นๆ ซึ่งล้วนพึ่งพาบริการข้อมูลของ Scale AI ธุรกิจหลักของ Scale AI คือการจัดหาข้อมูลที่มีป้ายกำกับที่แม่นยำจำนวนมาก
สาเหตุก็คือค้นพบความสำคัญของข้อมูลในอุตสาหกรรม AI ตั้งแต่เนิ่นๆ
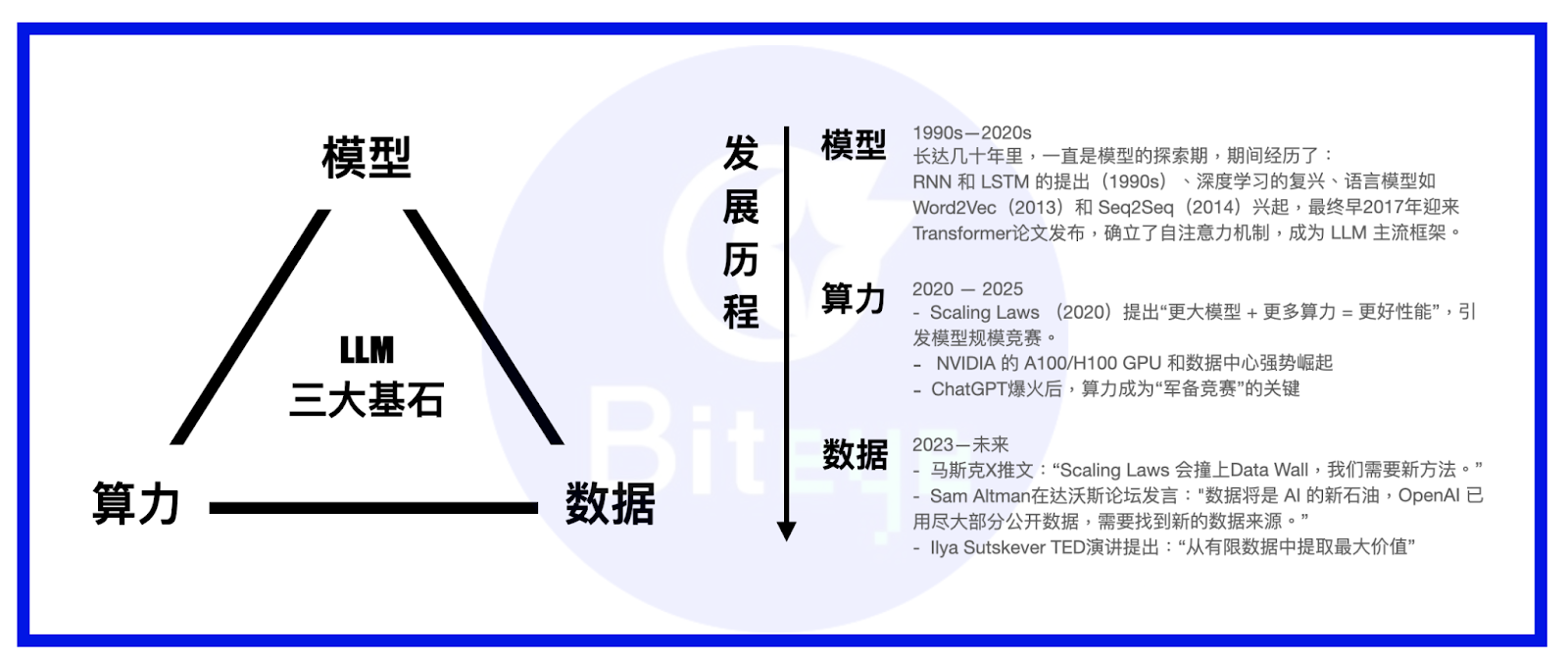
พลังการประมวลผล แบบจำลอง และข้อมูล คือสามเสาหลักของแบบจำลอง AI หากเปรียบเทียบแบบจำลองขนาดใหญ่กับบุคคล แบบจำลองก็คือร่างกาย พลังการประมวลผลก็คืออาหาร และข้อมูลก็คือความรู้/สารสนเทศ
ในช่วงหลายปีนับตั้งแต่การกำเนิดของ LLM จุดเน้นการพัฒนาของอุตสาหกรรมก็เปลี่ยนจากแบบจำลองไปสู่พลังการประมวลผล ปัจจุบัน แบบจำลองส่วนใหญ่ได้กำหนดกรอบการทำงาน (framework) ของแบบจำลอง โดยมีนวัตกรรมใหม่ๆ เกิดขึ้นเป็นครั้งคราว เช่น MoE หรือ MoRe ยักษ์ใหญ่หลายรายได้สร้าง Super Cluster ของตนเองเพื่อสร้างพลังการประมวลผลให้เสร็จสมบูรณ์ หรือลงนามในข้อตกลงระยะยาวกับบริการคลาวด์อันทรงพลังอย่าง AWS เมื่อบรรลุพลังการประมวลผลขั้นพื้นฐานแล้ว ความสำคัญของข้อมูลก็ค่อยๆ เด่นชัดขึ้น
ต่างจากบริษัท Big Data แบบดั้งเดิมของ To B ที่มีชื่อเสียงโดดเด่นในตลาดรองอย่าง Palantir Scale AI มุ่งมั่นที่จะสร้างรากฐานข้อมูลที่แข็งแกร่งสำหรับโมเดล AI ดังเช่นชื่อ ธุรกิจของบริษัทไม่ได้จำกัดอยู่แค่การขุดข้อมูลที่มีอยู่แล้ว แต่ยังมุ่งเน้นไปที่ธุรกิจการสร้างข้อมูลระยะยาวอีกด้วย นอกจากนี้ บริษัทยังพยายามจัดตั้งทีมฝึกอบรม AI ผ่านผู้เชี่ยวชาญ AI ในหลากหลายสาขา เพื่อมอบข้อมูลการฝึกอบรมที่มีคุณภาพดีกว่าสำหรับการฝึกอบรมโมเดล AI
การฝึกอบรมโมเดลแบ่งออกเป็นสองส่วน - ก่อนการฝึกอบรมและปรับแต่ง
ขั้นตอนก่อนการฝึกอบรมนั้นคล้ายกับกระบวนการเรียนรู้การพูดของทารกมนุษย์ โดยทั่วไปแล้ว สิ่งที่เราต้องการคือการป้อนข้อความ รหัส และข้อมูลอื่นๆ จำนวนมากที่ได้จากโปรแกรมรวบรวมข้อมูลออนไลน์ให้กับโมเดล AI โมเดลจะเรียนรู้เนื้อหาเหล่านี้ด้วยตัวเอง เรียนรู้ที่จะพูดภาษามนุษย์ (ในเชิงวิชาการเรียกว่าภาษาธรรมชาติ) และมีทักษะการสื่อสารขั้นพื้นฐาน
ส่วนการปรับแต่งนั้นคล้ายคลึงกับการไปโรงเรียน ซึ่งโดยปกติแล้วจะมีคำตอบและทิศทางที่ชัดเจนและถูกต้อง โรงเรียนจะฝึกฝนนักเรียนให้มีพรสวรรค์ที่แตกต่างกันไปตามตำแหน่งของพวกเขา นอกจากนี้ เราจะใช้ชุดข้อมูลที่ผ่านการประมวลผลล่วงหน้าและมีเป้าหมายเพื่อฝึกฝนแบบจำลองให้มีความสามารถตามที่เราคาดหวัง
ส่วนการปรับแต่งนั้นคล้ายคลึงกับการไปโรงเรียน ซึ่งโดยปกติแล้วจะมีคำตอบและทิศทางที่ชัดเจนและถูกต้อง โรงเรียนจะฝึกฝนนักเรียนให้มีพรสวรรค์ที่แตกต่างกันไปตามตำแหน่งของพวกเขา นอกจากนี้ เราจะใช้ชุดข้อมูลที่ผ่านการประมวลผลล่วงหน้าและมีเป้าหมายเพื่อฝึกฝนแบบจำลองให้มีความสามารถตามที่เราคาดหวัง

เมื่อถึงจุดนี้ คุณอาจคิดได้ว่าข้อมูลที่เราต้องการนั้นแบ่งออกเป็นสองส่วนด้วย
- ข้อมูลบางอย่างไม่จำเป็นต้องได้รับการประมวลผลมากเกินไป แค่เพียงพอก็พอ โดยปกติจะมาจากข้อมูลรวบรวมจากแพลตฟอร์ม UGC ขนาดใหญ่ เช่น Reddit, Twitter, Github, ฐานข้อมูลวรรณกรรมสาธารณะ ฐานข้อมูลส่วนตัวขององค์กร เป็นต้น
- ส่วนอื่นๆ เช่นเดียวกับตำราเรียนวิชาชีพ จำเป็นต้องมีการออกแบบและการคัดกรองอย่างรอบคอบ เพื่อให้มั่นใจว่าสามารถพัฒนาคุณสมบัติเฉพาะของแบบจำลองได้ ดังนั้นเราจึงต้องดำเนินงานที่จำเป็นบางอย่าง เช่น การทำความสะอาดข้อมูล การคัดกรอง การติดฉลาก และการป้อนกลับด้วยตนเอง
ชุดข้อมูลทั้งสองนี้ประกอบกันเป็นองค์ประกอบหลักของ AI Data อย่าประมาทชุดข้อมูลที่ดูเหมือนเทคโนโลยีต่ำเหล่านี้ กระแสหลักในปัจจุบันคือ เมื่อข้อได้เปรียบด้านพลังการประมวลผลในกฎ Scaling เริ่มไร้ประสิทธิภาพลงเรื่อยๆ ข้อมูลจะกลายเป็นเสาหลักที่สำคัญที่สุดสำหรับผู้ผลิตโมเดลขนาดใหญ่ต่างๆ เพื่อรักษาความได้เปรียบในการแข่งขัน
ในขณะที่ความสามารถของแบบจำลองได้รับการพัฒนาอย่างต่อเนื่อง ข้อมูลการฝึกอบรมที่ซับซ้อนและเป็นมืออาชีพมากขึ้นจะกลายเป็นตัวแปรสำคัญที่มีอิทธิพลต่อความสามารถของแบบจำลอง หากเราเปรียบเทียบการฝึกอบรมแบบจำลองกับการฝึกฝนปรมาจารย์ศิลปะการต่อสู้ ชุดข้อมูลคุณภาพสูงคือเคล็ดลับศิลปะการต่อสู้ที่ดีที่สุด (เพื่อเติมเต็มคำอุปมานี้ เราสามารถกล่าวได้ว่าพลังการประมวลผลคือยาครอบจักรวาล และแบบจำลองก็คือคุณสมบัติในตัวมันเอง)
จากมุมมองแนวตั้ง ข้อมูล AI ยังเป็นเส้นทางระยะยาวที่มีความสามารถในการเติบโตแบบก้าวกระโดด (snowball) ด้วยการสะสมงานก่อนหน้า สินทรัพย์ข้อมูลก็จะมีความสามารถในการทบต้น และจะได้รับความนิยมมากขึ้นเรื่อยๆ เมื่อมีอายุมากขึ้น
หากเปรียบเทียบกับทีมงานติดฉลากด้วยตนเองระยะไกลของ Scale AI ที่มีสมาชิกหลายแสนคนในฟิลิปปินส์ เวเนซุเอลา และสถานที่อื่นๆ แล้ว Web3 ก็มีข้อได้เปรียบโดยธรรมชาติในด้านข้อมูล AI และทำให้เกิดคำศัพท์ใหม่ DataFi ขึ้น
ในทางอุดมคติ ข้อดีของ Web3 DataFi มีดังต่อไปนี้:
1. อธิปไตยของข้อมูล ความปลอดภัย และความเป็นส่วนตัวได้รับการรับประกันโดยสัญญาอัจฉริยะ
ในระยะที่ข้อมูลสาธารณะที่มีอยู่กำลังจะถูกพัฒนาและหมดลง การขุดค้นข้อมูลที่ไม่เปิดเผยเพิ่มเติม แม้กระทั่งข้อมูลส่วนบุคคล ถือเป็นแนวทางสำคัญในการแสวงหาและขยายแหล่งข้อมูล ประเด็นนี้กำลังเผชิญกับปัญหาสำคัญในการเลือกความน่าเชื่อถือ นั่นคือ คุณจะเลือกใช้ระบบการซื้อกิจการของบริษัทขนาดใหญ่แบบรวมศูนย์และขายข้อมูลของคุณ หรือจะเลือกใช้วิธีการบล็อกเชน ถือครองทรัพย์สินทางปัญญาของข้อมูลไว้ในมือ และทำความเข้าใจอย่างชัดเจนผ่านสัญญาอัจฉริยะว่าใครใช้ข้อมูลของคุณ เมื่อใด และเพื่อวัตถุประสงค์ใด
ในเวลาเดียวกัน สำหรับข้อมูลที่ละเอียดอ่อน คุณสามารถใช้ zk, TEE และวิธีการอื่น ๆ เพื่อให้แน่ใจว่าข้อมูลส่วนตัวของคุณจะได้รับการจัดการโดยเครื่องจักรที่ปิดปากเท่านั้นและจะไม่รั่วไหล
2. ข้อได้เปรียบของการค้ากำไรทางภูมิศาสตร์ตามธรรมชาติ: สถาปัตยกรรมแบบกระจายฟรีดึงดูดแรงงานที่เหมาะสมที่สุด
บางทีอาจถึงเวลาที่ต้องท้าทายความสัมพันธ์ด้านการผลิตแรงงานแบบดั้งเดิม แทนที่จะมองหาแรงงานราคาถูกทั่วโลกอย่าง Scale AI จะดีกว่าหากใช้ประโยชน์จากคุณลักษณะแบบกระจายตัวของบล็อกเชน และเปิดโอกาสให้แรงงานที่กระจายอยู่ทั่วโลกมีส่วนร่วมในการส่งข้อมูลผ่านแรงจูงใจที่เปิดกว้างและโปร่งใส ซึ่งรับประกันโดยสัญญาอัจฉริยะ
สำหรับงานที่ใช้แรงงานเข้มข้น เช่น การติดฉลากข้อมูลและการประเมินแบบจำลอง การใช้ Web3 DataFi จะเอื้อต่อความหลากหลายของผู้เข้าร่วมมากกว่าแนวทางแบบรวมศูนย์ในการจัดตั้งโรงงานข้อมูล ซึ่งยังมีความสำคัญในระยะยาวในการหลีกเลี่ยงอคติของข้อมูลอีกด้วย
3. ข้อได้เปรียบที่ชัดเจนด้านแรงจูงใจและการชำระเงินของบล็อคเชน
จะหลีกเลี่ยงโศกนาฏกรรมของ "โรงงานเครื่องหนังเจียงหนาน" ได้อย่างไร? แน่นอนว่าเราควรใช้ระบบจูงใจที่มีป้ายราคาชัดเจนในสัญญาอัจฉริยะ เพื่อทดแทนความมืดมนในธรรมชาติของมนุษย์
ในบริบทของภาวะโลกาภิวัตน์ที่หลีกเลี่ยงไม่ได้ เราจะยังคงบรรลุข้อตกลงการค้าเสรีทางภูมิศาสตร์ที่มีต้นทุนต่ำต่อไปได้อย่างไร เห็นได้ชัดว่าการเปิดบริษัททั่วโลกนั้นยากกว่า ดังนั้น เหตุใดจึงไม่ก้าวข้ามอุปสรรคของโลกเก่าและหันมาใช้วิธีการชำระเงินแบบออนเชนแทน
4. เอื้อต่อการสร้างตลาดข้อมูลแบบครบวงจรที่มีประสิทธิภาพและเปิดกว้างมากขึ้น
"คนกลางที่แสวงหากำไรจากส่วนต่างราคา" เป็นปัญหาเรื้อรังสำหรับทั้งฝ่ายอุปทานและฝ่ายอุปสงค์ แทนที่จะปล่อยให้บริษัทข้อมูลส่วนกลางทำหน้าที่เป็นคนกลาง จะดีกว่าหากสร้างแพลตฟอร์มบนเครือข่ายผ่านตลาดเปิดอย่าง Taobao เพื่อให้ฝ่ายอุปทานและฝ่ายอุปสงค์ของข้อมูลสามารถเชื่อมต่อกันได้อย่างโปร่งใสและมีประสิทธิภาพมากขึ้น
ด้วยการพัฒนาของระบบนิเวศ AI แบบออนเชน ความต้องการข้อมูลออนเชนจะเพิ่มมากขึ้น แบ่งกลุ่ม และหลากหลายมากขึ้น มีเพียงตลาดแบบกระจายศูนย์เท่านั้นที่จะรองรับความต้องการนี้ได้อย่างมีประสิทธิภาพ และเปลี่ยนมันให้เป็นความเจริญรุ่งเรืองทางระบบนิเวศ
ด้วยการพัฒนาของระบบนิเวศ AI แบบออนเชน ความต้องการข้อมูลออนเชนจะเพิ่มมากขึ้น แบ่งกลุ่ม และหลากหลายมากขึ้น มีเพียงตลาดแบบกระจายศูนย์เท่านั้นที่จะรองรับความต้องการนี้ได้อย่างมีประสิทธิภาพ และเปลี่ยนมันให้เป็นความเจริญรุ่งเรืองทางระบบนิเวศ
เงินไหลไปที่ไหน ทิศทางก็อยู่ตรงนั้น นอกจาก Scale AI จะได้รับเงินลงทุน 14.3 พันล้านดอลลาร์จาก Meta และราคาหุ้นของ Palantir ที่พุ่งสูงขึ้นกว่า 5 เท่าภายในหนึ่งปีในโลก Web2 แล้ว DataFi ยังมีผลงานที่ดีมากในการจัดหาเงินทุน Web3 อีกด้วย ในบทความนี้ เราจะมาแนะนำโครงการเหล่านี้โดยสังเขป
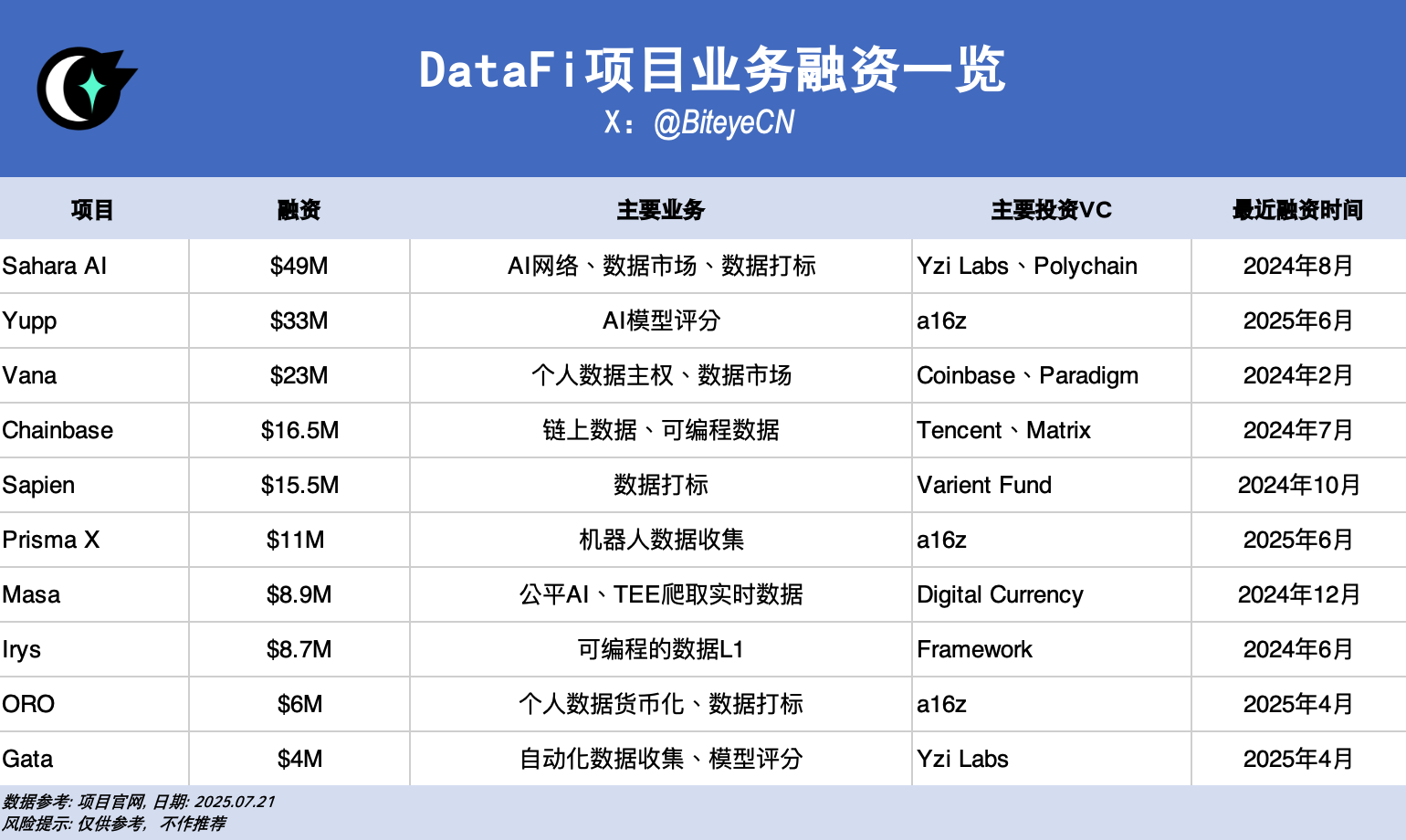
Sahara AI, @SaharaLabsAI ระดมทุนได้ 49 ล้านดอลลาร์
เป้าหมายสูงสุดของ Sahara AI คือการสร้างโครงสร้างพื้นฐาน AI แบบกระจายศูนย์และตลาดซื้อขาย ภาคส่วนแรกที่จะได้รับการทดสอบคือ AI Data เวอร์ชันเบต้าสาธารณะของ DSP (Data Services Platform) จะเปิดตัวในวันที่ 22 กรกฎาคม ผู้ใช้สามารถรับรางวัลโทเค็นได้จากการส่งข้อมูล การเข้าร่วมในการติดฉลากข้อมูล และงานอื่นๆ ลิงก์: app.saharaai.com
Yupp, @yupp_ai ระดมทุนได้ 33 ล้านดอลลาร์ Yupp คือแพลตฟอร์มรับคำติชมแบบจำลอง AI ที่รวบรวมคำติชมจากผู้ใช้เกี่ยวกับผลลัพธ์ของแบบจำลอง ภารกิจหลักในปัจจุบันคือผู้ใช้สามารถเปรียบเทียบผลลัพธ์ของแบบจำลองต่างๆ ในคำสั่งเดียวกัน แล้วเลือกแบบจำลองที่คิดว่าดีกว่า เมื่อทำภารกิจสำเร็จจะได้รับคะแนน Yupp ซึ่งสามารถนำไปแลกเปลี่ยนเป็นสกุลเงินดิจิทัลแบบคงที่ เช่น USDC ลิงก์: https://yupp.ai/
Vana, @vana ระดมทุนได้ 23 ล้านดอลลาร์
Vana มุ่งเน้นการแปลงข้อมูลส่วนบุคคลของผู้ใช้ (เช่น กิจกรรมบนโซเชียลมีเดีย ประวัติการเข้าชมเว็บไซต์ ฯลฯ) ให้เป็นสินทรัพย์ดิจิทัลที่สร้างรายได้ ผู้ใช้สามารถอนุญาตให้อัปโหลดข้อมูลส่วนบุคคลไปยังคลังข้อมูลสภาพคล่อง (DLP) ที่เกี่ยวข้องใน DataDAO ข้อมูลเหล่านี้จะถูกรวบรวมและนำไปใช้ในงานต่างๆ เช่น การฝึกอบรมโมเดล AI และผู้ใช้จะได้รับรางวัลโทเค็นที่เกี่ยวข้อง ลิงก์: https://www.vana.org/collectives
Chainbase, @ChainbaseHQ ระดมทุนได้ 16.5 ล้านดอลลาร์
ธุรกิจของ Chainbase มุ่งเน้นไปที่ข้อมูลบนเครือข่าย (on-chain data) และปัจจุบันครอบคลุมบล็อกเชนมากกว่า 200 แห่ง โดยเปลี่ยนกิจกรรมบนเครือข่ายให้เป็นสินทรัพย์ข้อมูลที่มีโครงสร้าง ตรวจสอบได้ และสร้างรายได้สำหรับการพัฒนา dApp ธุรกิจของ Chainbase ส่วนใหญ่ได้มาจากการจัดทำดัชนีแบบหลายเครือข่ายและวิธีการอื่นๆ และข้อมูลจะถูกประมวลผลผ่านระบบ Manuscript และโมเดล Theia AI ปัจจุบันผู้ใช้งานทั่วไปไม่ได้มีส่วนร่วมมากนัก
Sapien, @JoinSapien ระดมทุนได้ 15.5 ล้านเหรียญสหรัฐ
Sapien มุ่งมั่นที่จะแปลงความรู้ของมนุษย์ให้เป็นข้อมูลฝึกอบรม AI คุณภาพสูงในวงกว้าง ทุกคนสามารถวิเคราะห์ข้อมูลบนแพลตฟอร์มและรับรองคุณภาพของข้อมูลผ่านการตรวจสอบความถูกต้องของเพื่อน ขณะเดียวกัน ผู้ใช้ยังได้รับการสนับสนุนให้สร้างชื่อเสียงในระยะยาวหรือสร้างพันธสัญญาผ่านการ Staking เพื่อรับรางวัลมากขึ้น
ลิงก์: https://earn.sapien.io/#hiw
Prisma X, @PrismaXai ระดมทุนได้ 11 ล้านดอลลาร์สหรัฐฯ Prisma X ต้องการเป็นเลเยอร์ประสานงานแบบเปิดสำหรับหุ่นยนต์ ซึ่งการรวบรวมข้อมูลทางกายภาพเป็นหัวใจสำคัญ ปัจจุบันโครงการนี้ยังอยู่ในช่วงเริ่มต้น ตามรายงานที่เพิ่งเผยแพร่ การเข้าร่วมอาจรวมถึงการลงทุนในหุ่นยนต์เพื่อรวบรวมข้อมูล การควบคุมข้อมูลหุ่นยนต์จากระยะไกล และอื่นๆ ปัจจุบันมีแบบทดสอบที่อิงจากรายงานดังกล่าว ซึ่งคุณสามารถเข้าร่วมเพื่อรับคะแนน ลิงก์: https://app.prismax.ai/whitepaper
Masa @getmasafi ระดมทุนได้ 8.9 ล้านดอลลาร์
Masa เป็นหนึ่งในโครงการซับเน็ตชั้นนำในระบบนิเวศ Bittensor และปัจจุบันดำเนินการซับเน็ตข้อมูลหมายเลข 42 และซับเน็ตตัวแทนหมายเลข 59 ซับเน็ตข้อมูลนี้มุ่งมั่นที่จะมอบการเข้าถึงข้อมูลแบบเรียลไทม์ ปัจจุบัน นักขุดส่วนใหญ่รวบรวมข้อมูลแบบเรียลไทม์บน X/Twitter ผ่านฮาร์ดแวร์ TEE สำหรับผู้ใช้ทั่วไป ความยากและต้นทุนในการเข้าร่วมค่อนข้างสูง
Irys, @irys_xyz ระดมทุนได้ 8.7 ล้านดอลลาร์
Irys มุ่งเน้นไปที่การจัดเก็บข้อมูลและการประมวลผลข้อมูลแบบตั้งโปรแกรมได้ โดยมุ่งหวังที่จะนำเสนอโซลูชันที่มีประสิทธิภาพและต้นทุนต่ำสำหรับ AI แอปพลิเคชันแบบกระจายศูนย์ (dApps) และแอปพลิเคชันอื่นๆ ที่ต้องใช้ข้อมูลจำนวนมาก ในแง่ของการมีส่วนร่วมของข้อมูล ผู้ใช้ทั่วไปยังไม่สามารถมีส่วนร่วมได้มากนักในปัจจุบัน แต่มีกิจกรรมมากมายให้เข้าร่วมในขั้นตอนการทดสอบเครือข่ายในปัจจุบัน
ลิงค์: https://bitomokx.irys.xyz/
ORO @getoro_xyz ระดมทุนได้ 6 ล้านเหรียญสหรัฐ
สิ่งที่ ORO ต้องการทำคือการเสริมศักยภาพให้ประชาชนทั่วไปสามารถมีส่วนร่วมในโครงการ AI ได้ วิธีการสนับสนุนประกอบด้วย: 1. เชื่อมโยงบัญชีส่วนตัวของคุณเพื่อร่วมบริจาคข้อมูลส่วนบุคคล ซึ่งรวมถึงบัญชีโซเชียล ข้อมูลสุขภาพ บัญชีอีคอมเมิร์ซ และบัญชีการเงิน 2. ดำเนินการงานด้านข้อมูลให้เสร็จสมบูรณ์ ขณะนี้เครือข่ายทดสอบออนไลน์แล้ว และคุณสามารถเข้าร่วมได้
ลิงค์: app.getoro.xyz
Gata @Gata_xyz ระดมทุนได้ 4 ล้านเหรียญสหรัฐ
Gata ซึ่งวางตำแหน่งเป็นเลเยอร์ข้อมูลแบบกระจายอำนาจ ปัจจุบันมีผลิตภัณฑ์หลักสามรายการให้มีส่วนร่วม: 1. Data Agent: ชุด AI Agent ที่สามารถรันและประมวลผลข้อมูลโดยอัตโนมัติตราบใดที่ผู้ใช้เปิดหน้าเว็บ 2. AII-in-one Chat: กลไกที่คล้ายกับการประเมินโมเดลของ Yupp เพื่อรับรางวัล 3. GPT-to-Earn: ปลั๊กอินเบราว์เซอร์ที่รวบรวมข้อมูลการสนทนาของผู้ใช้บน ChatGPT
ลิงก์: https://app.gata.xyz/dataAgent
https://chromewebstore.google.com/detail/hhibbomloleicghkgmldapmghagagfao?utm_source=item-share-cb
ปัจจุบัน อุปสรรคในการเข้าสู่ตลาดสำหรับโครงการเหล่านี้โดยทั่วไปยังไม่สูงนัก แต่ต้องยอมรับว่าเมื่อผู้ใช้และระบบนิเวศน์เหนียวแน่นขึ้น ข้อได้เปรียบของแพลตฟอร์มก็จะเพิ่มขึ้นอย่างรวดเร็ว ดังนั้น ในช่วงเริ่มต้น ควรมุ่งเน้นไปที่แรงจูงใจและประสบการณ์ของผู้ใช้ การดึงดูดผู้ใช้ให้เพียงพอเท่านั้นจึงจะสามารถสร้างธุรกิจข้อมูลขนาดใหญ่ได้
อย่างไรก็ตาม เนื่องจากเป็นโครงการที่ใช้แรงงานจำนวนมาก แพลตฟอร์มข้อมูลเหล่านี้จึงควรพิจารณาถึงวิธีการจัดการแรงงานและรับประกันคุณภาพของข้อมูลที่ส่งออกไปพร้อมกับการดึงดูดแรงงานด้วย ท้ายที่สุด ปัญหาที่พบบ่อยของโครงการ Web3 หลายโครงการคือ ผู้ใช้ส่วนใหญ่บนแพลตฟอร์มเป็นเพียงผู้แสวงหากำไรอย่างไร้ความปราณี พวกเขามักจะเสียสละคุณภาพเพื่อผลประโยชน์ระยะสั้น หากพวกเขาได้รับอนุญาตให้เป็นผู้ใช้หลักของแพลตฟอร์ม เงินที่ไม่ดีก็จะขับไล่เงินที่ดีออกไปอย่างหลีกเลี่ยงไม่ได้ และท้ายที่สุดแล้ว คุณภาพของข้อมูลก็ไม่สามารถรับประกันได้และไม่สามารถดึงดูดผู้ซื้อได้ ปัจจุบัน เราได้เห็นแล้วว่าโครงการต่างๆ เช่น Sahara และ Sapien ได้ให้ความสำคัญกับคุณภาพของข้อมูลและมุ่งมั่นที่จะสร้างความสัมพันธ์ความร่วมมือที่ดีในระยะยาวกับแรงงานบนแพลตฟอร์ม
นอกจากนี้ การขาดความโปร่งใสยังเป็นอีกปัญหาหนึ่งของโครงการแบบออนเชนในปัจจุบัน อันที่จริง สามเหลี่ยมที่เป็นไปไม่ได้ของบล็อกเชนได้บังคับให้หลายโครงการต้องดำเนินตามแนวทาง "การรวมศูนย์ขับเคลื่อนการกระจายอำนาจ" ในช่วงเริ่มต้น แต่ปัจจุบัน โครงการออนเชนจำนวนมากขึ้นเรื่อยๆ กลับทำให้ผู้คนรู้สึกเหมือน "โครงการ Web2 แบบเก่าใน Web3" กล่าวคือ มีข้อมูลสาธารณะที่สามารถติดตามได้น้อยมากบนเชน และแม้แต่แผนงานก็ยังยากที่จะเห็นการกำหนดความเปิดกว้างและความโปร่งใสในระยะยาว สิ่งนี้ส่งผลเสียต่อการพัฒนา Web3 DataFi ในระยะยาวอย่างไม่ต้องสงสัย และเราหวังว่าโครงการอื่นๆ จะคงไว้ซึ่งเจตนารมณ์ดั้งเดิมและเร่งกระบวนการของความเปิดกว้างและความโปร่งใสให้เร็วขึ้น
สุดท้ายนี้ เส้นทางการนำ DataFi ไปใช้อย่างแพร่หลายควรแบ่งออกเป็นสองส่วน ส่วนแรกคือการดึงดูดผู้เข้าร่วม toC ให้เข้าร่วมเครือข่าย ก่อให้เกิดพลังใหม่ด้านวิศวกรรมการรวบรวม/สร้างข้อมูลและผู้บริโภคของเศรษฐกิจ AI ก่อให้เกิดวงจรปิดเชิงนิเวศ ส่วนที่สองคือการได้รับการยอมรับจากกระแสหลักในปัจจุบันสู่บริษัท B เพราะในระยะสั้น พวกเขาคือแหล่งที่มาหลักของคำสั่งซื้อข้อมูลขนาดใหญ่ที่มีเงินทุนหนา ในเรื่องนี้ เรายังได้เห็นความก้าวหน้าที่ดีของ Sahara AI, Vana และอื่นๆ อีกด้วย
หากจะพูดให้เห็นภาพชะตากรรมมากขึ้น DataFi เป็นเรื่องของการใช้ปัญญาของมนุษย์เพื่อบ่มเพาะปัญญาของเครื่องจักรในระยะยาว ขณะเดียวกันก็ใช้สัญญาอัจฉริยะเป็นสัญญาเพื่อให้แน่ใจว่าแรงงานที่ใช้ปัญญาของมนุษย์นั้นทำกำไรได้ และท้ายที่สุดก็ได้รับผลตอบรับจากปัญญาของเครื่องจักร
หากคุณมีความวิตกกังวลเกี่ยวกับความไม่แน่นอนของยุค AI และหากคุณยังมีอุดมคติเกี่ยวกับบล็อคเชนท่ามกลางความขึ้นๆ ลงๆ ของโลกสกุลเงินดิจิทัล การเดินตามรอยกลุ่มยักษ์ใหญ่ด้านเงินทุนและเข้าร่วม DataFi ถือเป็นตัวเลือกที่ดีในการเดินตามกระแสนี้


ความคิดเห็นทั้งหมด